
By LUKE OAKDEN-RAYNER, MD
One big theme in AI research has been the idea of interpretability. How should AI systems explain their decisions to engender trust in their human users? Can we trust a decision if we don’t understand the factors that informed it?
I’ll have a lot more to say on the latter question some other time, which is philosophical rather than technical in nature, but today I wanted to share some of our research into the first question. Can our models explain their decisions in a way that can convince humans to trust them?
Decisions, decisions
I am a radiologist, which makes me something of an expert in the field of human image analysis. We are often asked to explain our assessment of an image, to our colleagues or other doctors or patients. In general, there are two things we express.
- What part of the image we are looking at.
- What specific features we are seeing in the image.
This is partially what a radiology report is. We describe a feature, give a location, and then synthesise a conclusion. For example:
There is an irregular mass with microcalcification in the upper outer quadrant of the breast. Findings are consistent with malignancy.
You don’t need to understand the words I used here, but the point is that the features (irregular mass, microcalcification) are consistent with the diagnosis (breast cancer, malignancy). A doctor reading this report already sees internal consistency, and that reassures them that the report isn’t wrong. An common example of a wrong report could be:
Irregular mass or microcalcification. No evidence of malignancy.
In this case, one of the sentences must be wrong. An irregular mass is a sign of malignancy. With some experience (and understanding of grammar), we know that the first sentence is probably wrong; the “No” that should have started the report was accidentally missed by the typist or voice recognition system.
I spoke a while ago about the importance of “sanity checking” in image analysis, and this is just as true of human-performed analysis as it is of deep learning models. The fact that the diagnosis and the image features that informed it match is a simple sanity check that clinicians can use to confirm the accuracy of the report. Indeed, every month or two I get a call from a clinician asking me to clarify a report where a transcription error slipped by me.
Location, location, location

Like cartographers, radiologists who can’t explain locations are pretty useless.
The second key feature is location, which forms a second level of sanity check. If describing the features can confirm the report is consistent, describing the location can confirm that the image matches the report. For example, another common radiology error:
The fracture of the 3rd metacarpal of the right foot is unchanged.
For the non-medicos, the metacarpals are in the hands, and the metatarsals are in the feet. The location described is clearly wrong, but it is usually obvious what was meant (since the patient has a sore foot). But if the clinician had ordered foot and hand x-rays, they could check the images and solve this error themselves.
Location information allows the clinician to confirm the report matches the image. They might not know what is specifically wrong in the image, since they aren’t an imaging specialist, but if the report is consistent and describes a visible abnormality on the image then the clinician can be much more confident about the report.
So, the two key aspects of a good radiology report are to describe abnormalities in terms of “what” and “where”.
Interestingly, this is how the human brain deals with images. There appear to be distinct pathways from the visual cortex to the rest of the brain focused on “what” and “where”, and these appear to be the primary mechanisms our brains use to turn light into visual information. So for what it is worth, neuroscience supports how we describe images.

That is just your interpretation
Deep learning is a black box, according to many. Most models output a score from 0 to 1, which relates to how confident the model is of the decision. It isn’t even the probability of the outcome in question. It is just something like an ordered list, where higher numbers are more likely than lower numbers to have the outcome.
Of course, this means the black-box criticism of deep learning is pretty valid. The output is nearly uninterpretable. The score is just an arbitrary value that gives you a vague feel for how confident the model is.
There are a range of proposed solutions:
- Calibration is where you turn the arbitrary score into a true probability. It makes more sense if a score of 0.7 means the case has a 70% chance of having a disease, but it doesn’t help us understand the decision at all. Let’s ignore this one.
- Image retrieval/clustering, where you have some way of showing the human a bunch of other similar cases. The human is left to identify similarities to infer what the model was interested in. Unsurprisingly, this works terribly as a way of explaining a decision. We’ll ignore this too.
- Saliency maps are heatmaps that identify where in the image the most important pixels were. This sounds a lot more like what we need to make decisions explainable (at least the “where” part of decisions), but has some caveats.
- Hallucinations are visualisations of the features themselves, what each neuron in the model is looking for. Again, great idea to show that “what”, but with caveats as well.
So hot right now
Heatmaps are everywhere. Every medical deep learning paper, every conference talk, every blog post. They look cool. Or hot. Whatever.

Saliency maps, like these ones from Zhou et al, show which part of the image is most relevant to the question.

Heatmaps seem like they answer half of “where”, and they do, sorta. But anyone who has worked with heatmaps will tell you, they aren’t always easy to interpret. This turns out to be a major weakness for an interpretability method

In this work from a GroundAI research blog, we can see that saliency maps can be a bit janky. What do the saliency maps mean? Why are those specific spots relevant to being in a room, or the gender and number of people present?
It gets even worse when we deal with negations. What does it mean to highlight the most important area of an x-ray that shows there is no fracture?
Overall, saliency maps are great, but perhaps their success has been more about how good they look than how useful they are.
Hallucinating for fun and profit
The most common approach to explaining what a model is looking for when making a decision is to generate visualisations of the specific features that it detects. Each neuron in a neural network learns a specific filter, a feature detector that responds to a certain pattern in the images. Since we can work out which neurons most contribute to the decision, it is just a matter of working out what the most active neurons respond to.
This process is often given whimsical names like dreaming or hallucination, partially because it has some similarities to what we understand of these neurological processes, but mostly because the images that come out from these methods look bizarre.

Feature/activation visualisations are great if your subject is an eldritch horror from the icy void beyond the stars. Otherwise, not so much.
I totally love this avenue of research because it is just interesting, but there is a huge problem when it comes to offering explanations with these methods; you still need to interpret the pictures that come out.
Lets say we want to know what a model is seeing when it decides certain objects are present in images, so we get it to hallucinate some features for us. This is what we see:

Hmm… I can see object-y looking things, but it isn’t really obvious what the key elements of the decisions are. I suppose I can say that when it says there is a banana, it is looking for a thing that I think looks like a banana.
This is reassuring, but it falls flat as an explanation.
Side note: if you want to know more about feature visualisation, check out some of Chris Olah and team’s work on distill.pub here. Even cooler, their attempt at combining what and where (and even why, they also look at feature importance/attribution) with visualisation techniques here. This is probably the closest research to what we have attempted. This is what it looks like:

Sorry that this will be unreadable on phones. It is super cool, highlighting somewhat recognisable features by location … but it is still a long way from something you can glance at and say “yep, that seems right”. Great for exploring what a network is doing, not so good for explaining decisions.
Our solution
We think there is a better way, and it is all about how humans explain their visual experience to each other. Just like AI systems, other humans are black boxes to us. We can’t experience their internal worlds. Honestly, we are black boxes to ourselves as well. We have no idea how our visual cortex recognises a certain object, and we can’t get root access to do troubleshooting when it messes up. Like with pareidolia:

Attack of the adversarial capsicums.
All we can use to understand other peoples decisions about their visual experience is what they tell us.
It turns out that how other people explain their visual decisions is good enough. In fact, that is what a radiology report is; the explanation of a visual experience from someone the receiving doctor of patient usually doesn’t know and won’t directly talk to. The report is all of the explanation they will get, and no-one argues that radiology is a black box or untrustworthy.
So we have a solution to intrepretability; let’s make reports!
In an ideal world, we would just produce perfect radiology reports from images. It is possible, just like image captioning:

The only problem is that so far we haven’t been able to do it. The problem is complex enough that even with quite large datasets, the text we can produce is mostly gibberish (albeit improving slowly). There is too much variation to learn, and deep learning is inefficient enough that to actually solve a task like this we might need a dataset larger than all images ever taken on the planet.

TieNet is the most recent and best attempt (paper accepted at CVPR this year). But there are problems that make the generated text nearly useless as an explanation. In this example (there are lots more in the paper), from left to right: 1) bad grammar, repetition. 2) bad grammar. 3) wrong side. 4) doesn’t describe location of nodule.
Despite our best efforts, any doctor receiving a report like those produced in this sort of “just throw data at it” research would not accept the findings. Most of the time they are barely readable.
The problem is that the reports are too variable. Each doctor uses slightly different terminology and grammar, and even the same doctor would report the same study differently if they were asked to do it again. But while the language of radiology reports is highly complex, believable visual explanations are very simple.
The key motivation for our work is that when humans explain a visual experience to other humans, they usually only mention a few key features. In fact, the number of features worth mentioning for any decision is incredibly small.
Here are a few examples for how a human might describe an image:

“There is a large horse-like animal with black and white stripes.”

“There is a pony-sized cat with a red-brown mane.”
In both of these examples, the description is what we doctors might call pathognomonic; it specifies exactly what is in the picture, despite being very short. Without the picture, you already know what is in it.
In radiology it is the same. Most disease you could care to identify are defined by under five key findings. Stroke? Loss of grey-white differentiation. Breast cancer? Irregular mass, micro-calcification, architectural distortion. Appendicitis? Enlarged appendix, fat-stranding.
It turns out that most visual explanations are very short, with very few key elements.
For the image analysis people among us, it should be obvious that these descriptions are actually totally inadequate. For example in the explanation that the above pictures are a zebra and a lion, we are left with a ton of unanswered questions. What is an animal? How does it mean to be “horse-like” or “cat-like”? How big is a large animal?
I’ve written a bit about how information theory applies to image analysis. In particular, I’ve noted that humans not only compress information into text to be able to communicate, but we also encode information. This means the messages we give each other are no longer self-contained – they require an external decoder to understand them. For visual descriptions, this decoder is the brain of the person we are talking to. Since they already know what an animal is, and what stripes are, we don’t need to include explanations of these terms in our messages. This means we can cheat; we can piggy-back on the knowledge of the receiver.
Let’s look at another example:
“There are two black and white grazing animals on the grass.”
What do you think of? Probably something like this –

But the exact same sentence could describe our zebra picture. Both sentences contain roughly the same amount of information, but the earlier description of a zebra is much more useful as an explanation.
This is one of the tricky parts of information theory as an applied science. Information is supposed to have a set amount of value. A single bit of information can answer one yes/no question. But if you have an encoder, some information is more valuable than others. Knowing that the black-and-white pattern is stripes is more valuable than knowing the animals are in a field, because our decoder (the adult brain) contains the knowledge that both zebras and cows live in fields, and cows are much more common (in real life and in pictures). Our code tells us the second sentence should be about cows, but the first should be about zebras.
Getting into your head
Current day AI systems can’t replicate everything brains do. We can’t take our understanding of the visual world to teach an AI to decode (and encode) descriptions as well as a human does. But we don’t need to! With a small amount of elbow grease, we can make our models copy what a human would do, without needing to encode or decode itself.
It is very simple. If we can teach our models to recognise whether black and white on animals is in stripes or patches, or whether animals are in a field, which one is worth teaching? We already saw that the former is more useful as an explanation than the latter, so all we need to do is select the high-yield elements of a report and get the model to learn them. We use our knowledge as radiologists to identify the salient phrases and words for any given medical task, and then we relabel the dataset with them.
In our paper, we focused on the problem of hip fracture detection. We already built a model that performs this task exceedingly well (AUC = 0.994!), largely because we put in a ton of effort cleaning the large dataset of around 50,000 hip images. In that work, the dataset was already labeled with the presence or absence of a fracture as well as the fracture location.
As I have mentioned previously, providing more information to deep learning models via fine-grained labels is almost always beneficial. We found that training the system to identify not only fractures but the intra-capsular and extra-capsular location of fractures improved diagnostic performance quite a bit. We actually had even finer-grained location labels (shown below), but the subgroups were a bit small to help in training the detection model.

The label scheme for describing fracture location in our work.
Given that an explanation is a mix of location and characterisation, just training the model for high performance already meant we had made a lot of the labels needed to produce good descriptions. Now we just needed the character of the fracture.
There are lots of words used to describe the character of fractures, but there are only a few important ones. How a fracture is to be treated, whether it needs an operation, is usually determined based on displacement and comminution (fragmentation).

The label scheme for describing fracture character in our work.
The degree of displacement also matters, so we included the adjectives subtle, mild, moderate, and severe with that term.
With these terms identified, we simply created sentences with a fixed grammatical structure and a tiny vocabulary (26 words!). We stripped the task back to the simplest useful elements. For example: “There is a mildly displaced comminuted fracture of the left neck of the femur.” Using sentences like that we build a RNN to generate text*, on top of the detection model.
And that is the research in a nutshell! No fancy new models, no new maths or theoretical breakthroughs. Just sensible engineering to make the task tractable.
All of this is well and good, but the question is, how well does it work?
Results

In one of the least surprising results ever presented, our model can recreate highly simplified sentences better than complex ones. BLEU scores say how well the words match the “correct” answer. As you can see, training on the original reports rarely produces strings of more than a few words which match the ground truth. With our simplified sentences the degree of matching is super high.
But BLEU scores and similar are widely criticised in natural language processing tasks for good reason. They don’t capture the meaning of the text, all they measure is word-matching. So we looked at that too.

A radiologist (me) looked through 200 random fracture/sentence combos and judged whether they contained the right content in terms of describing the location and character of the fractures. The model did really well!
The location description was a bit less likely to be correct (99 vs 90%) but they were almost all “off-by-one” errors, which are not very important. In particular, sub-capital fractures called trans-cervical, or trans-cervical fractures called inter-trochanteric. This can be difficult for humans, especially with only a frontal x-ray.
The original reports on the other hand often failed to describe the character at all. They didn’t mention comminution or displacement when it was present, often simply saying things like “there is a trans-cervical fracture of the femur”. This obviously isn’t a big deal since non-radiologist doctors and patients aren’t storming radiology clinics demanding better descriptions, but it is nice to see the output of a medical AI system clearly being more consistent than humans.
But none of this answers our major question: do doctors accept these descriptions as “interpretable answers”? To test this we gathered 5 doctors with between 3 and 7 years of postgraduate experience. These are the exact sort of doctors who read a lot of radiology reports, working in hospital wards, emergency departments, and intensive care units.
We asked them to assume the diagnosis of a fracture had come from an unknown source, and asked them to rate how well they trusted the explanation. We showed them saliency maps (since this is the current state of the art in most medical AI papers), the generated sentences, and the combination of both the saliency map and the sentences.

The doctors all vastly preferred sentences to saliency maps, and actually preferred the combination most of all.
So you can judge it all for yourself, here is a bunch of examples (randomly selected, not cherry picked). The words highlighted in red were judged to be incorrect, and the sentences highlighted in orange did not contain an adequate description of the fracture.
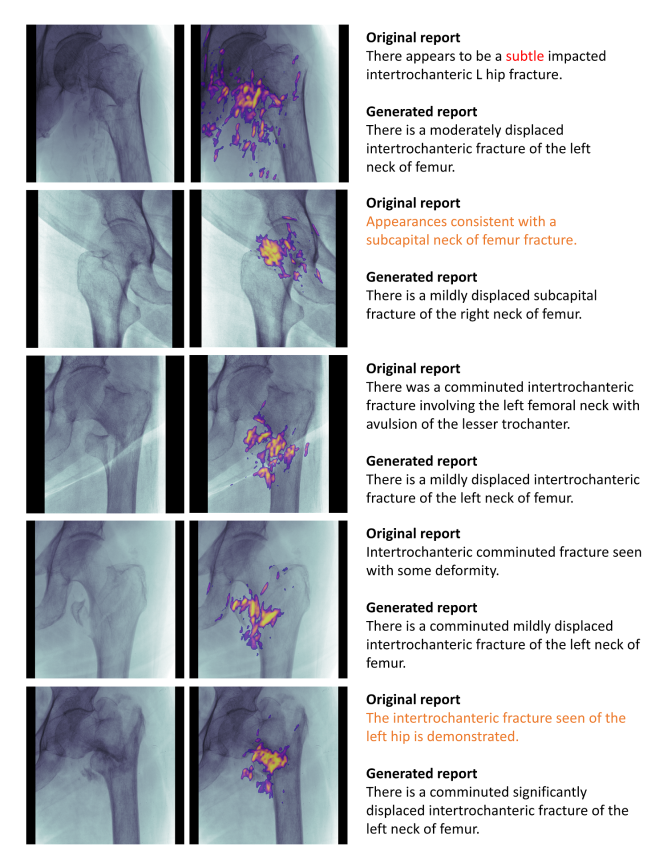


Real talk
We think we have shown that trying to generate simplified but explanatory text is a great way to convince humans that an AI system is being sensible, and so they can trust the decisions.
As mentioned earlier, this is not actually a complete explanation for the image (it relies on knowledge like what comminution is). We are piggy backing on the knowledge of the reader (their decoder) to make the task tractable. But in our defense, we do note that humans do not expect more complex explanations than what our system produces
One particularly interesting thing to note about this work though is that we never retrained the image model. This means that the image model had already learned to identify fine-grained location and fracture characteristics, despite never being trained on them. This is a pretty cool finding, and should be somewhat reassuring whenever the next “AI is a black box” panic arises. Yes, it is a black box, but what is in there is pretty sensible.
Finally, the question of the effort required. The big benefit of saliency maps is that once you have the code, it takes no effort at all. Some computation cycles, but that is it. Since we had to do some extra labeling, there is an additional burden which will fall on the experts you get to label your cases.
But there is a really nice property of human image analysis that makes it all work just dandy. While identifying whether a hip is fractured or not can be very hard, even for experts, describing a known fracture is super easy and more importantly, super quick. Labeling the entire set of over 4000 fractures with these additional labels took me around 3 hours. Producing the original dataset took 6 months. The marginal cost is next to nothing.
Can this approach be applied more broadly? We think so. Take a retinopathy dataset and label whether an image contains microaneurysms, hard exudates, and neovascularity. Take a lung CT dataset and label whether the nodules are small, large, spiculated, or cavitating. Take ImageNet and label colours, shapes, and so on.
Or, label green and brown, flat and spiky. Then we will know why Janet thought cactuses were manilla folders.
Obviously this is one set of experiments in one dataset, and should be interpreted as such. But the general idea of text explanations being more convincing than current interpretability methods is something worth exploring further.
TL:DR
- AI systems are “black-boxes”. Their decisions are hard to understand, and current methods are not very good at convincing humans to trust them.
- Humans explain their decisions to each other through language, and this is considered sufficient to be trustworthy.
- Language explanations of visual decisions are usually very simple, because we can rely on the inbuilt knowledge of our audience to interpret the basics. We can do the same with AI, training systems to produce very simple text that is convincing to humans.
- In our work human doctors found this approach trustworthy, and much preferred to saliency maps (the dominant approach in interpretability methods).
- While this approach requires some relabeling of data, the marginal cost is tiny. It took less than 1% of the time already taken to produce the dataset.
* There is an obvious question here: why an RNN**? Why not just add a multi-class softmax on the top of the CNN and produce the text post-hoc? You totally could! We considered it, but we didn’t think there was a good theoretical justification either way (with a task this simple, performance should be the same) and we wanted the flexibility of RNN language generation for future proofing. If we want to add new words, grammatical structures, and so on, we just supply more data rather than having to change the model. This justification is reasonably weak, but it really doesn’t matter. The point of the research isn’t the model, it is the approach to the problem.
** The interesting thing about this question is that it seems to imply that using a softmax layer should be the default position, and using an RNN needs justification. Not sure why this position would be valid, they both do essentially the same thing. Shrugs
Luke Oakden-Rayner is a radiologist (medical specialist) in South Australia, undertaking a Ph.D in Medicine with the School of Public Health at the University of Adelaide. This post originally appeared on his blog here.
Categories: Uncategorized







