
By ANISH KOKA
Physicians have been making up numbers longer than people have been guessing weights at carnivals. How much does this statin lower the chances of a heart attack? How long do I have to live if I don’t get the aortic valve surgery?
In clinics across the land confident answers emerge from doctors in white coats. Most of the answers are guesses based on whatever evidence about the matter exists applied to the patient sitting in the room. The trouble is that the evidence base used to be the provenance of experts and anecdotes that have in the past concluded leeches were good for pneumonia.
And so came the randomized control trial to separate doctors from homeopaths. Random assignment seeks to achieve balance between two groups for everything but the treating variable to isolate the effect of the treatment. But does randomization really guarantee a balance between groups? At least the known confounders may be measured in the two groups, but what about unknown confounders?
Consider some examples:
Blood stream infections are currently treated by antibiotics targeted towards the specific organism found in the blood. The distribution of organisms within the blood stream is as follows:

Vancomycin is active against S.aureus, Coag Negative Staph (CoNS), and other gram (+) organisms. Cefepime is active against Gram negatives. Now imagine a world where there was no understanding of the different organisms that caused blood stream infections, and an earnest researcher seeking to do right by patients with blood stream infections ran a trial which randomized all blood stream infections to either Vancomycin or Cefepime. In the beautiful table that would accompany the published article to demonstrate balance via randomness of age, sex, gender and perhaps some type of frailty index, the most important factor – the type of organism – would be missing. What we don’t know in this case drives the outcome. A trial with a high population of homeless patients could have a very different distribution of organisms than a trial performed in suburban patients in the rich Mainline of Philadelphia. The inability to generalize a trial of mainline moms to other populations means a trial fails to have external validity. There are other problems as well. Perform a large trial that combines the homeless with suburban soccer moms and the average treatment effect loses meaning unless you are a clinician that may randomly take care of a mainline mom or a homeless person on any given day.
But if we knew of this difference in organism prevalence between populations prior to trial initiation, and an analysis of these groups was prespecified, at least there is hope. Our statistical friends could then very easily account for the difference at the end of the study. But what if we were unaware of this difference? We would then have to hope that randomization ensured that unknown confounders spread themselves similarly between the two groups. Statisticians, interestingly, are unconcerned about the spread of unknown confounders between two groups.
A game of dice
Stephen Senn, the grand emperor of statisticians famously explains this using a game where 2 fair six sided dice are thrown, and the observer is asked to guess the probability the sum of the die will be 10 under three conditions. In the first condition we are asked to guess the probability of this as the two dice are thrown. Since there are only three out of thirty six combinations that will work (4/6, 5/5, 6/4), the probability is 3/36, or 1/12th.
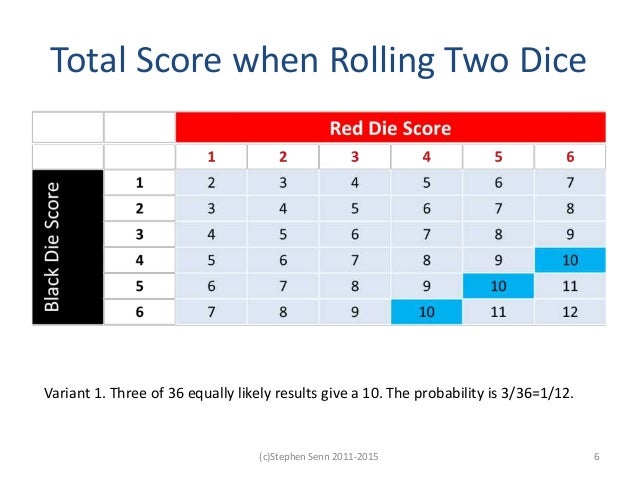
In the second condition, the first dice is cast and the number revealed prior to guessing. In this case if the first die roll is 1, 2 or 3, the probability of getting a 10 is zero. But if the first die cast is a 4,5 or 6 the probability of a 10 is 3/18 or 1/6. In the last condition (Variant 3), the first die is cast but the observer is not told what the number is. Since we don’t know what the first die roll is, the probability here is the same as the first condition.
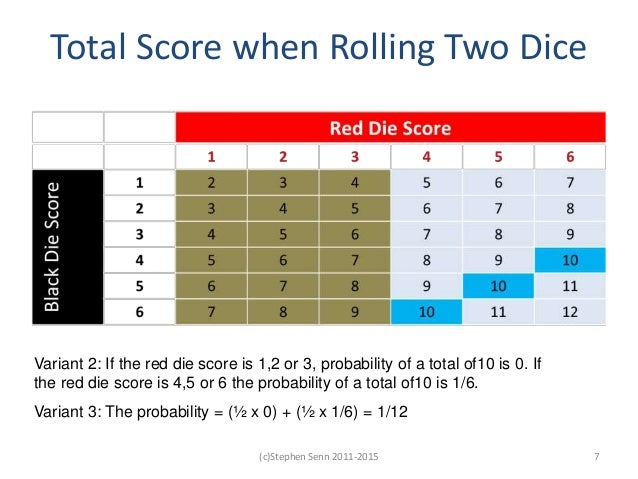
The moral of the story, Senn tells us, is that we should not throw knowledge away once attained (we can’t and shouldn’t pretend to unsee the roll of the first die), but not knowing doesn’t create a fatal problem because the probability distribution of an outcome is the same whether there is an unknown confounder or not. So covariates/confounders that could have an effect don’t really have to be balanced between the two groups as long as the distribution of the outcome in the two groups is the same.
This sounds good, but to return to the blood stream infection example, this is like saying that it doesn’t matter what the distribution of vancomycin susceptible organisms were between two groups as long as we don’t know the distribution of organisms. Statisticians get frustrated with this line of reasoning from ‘algebra challenged’ physicians. I sympathize. I’m frustrated with statisticians that are ‘medically challenged’.
Regardless, we have to operate and deal with what we don’t know in the real world, and the point that I gather from Senn is that it is always better to know, but if you don’t know, randomization is your best bet to getting at the truth. It would also seem that randomization is the best chance for an even distribution of unknown confounders between groups.
Unfortunately, even with all of this a perfectly balanced RCT is no protection to falling prey to false inferences.
Purposeful blindness
Consider the real life case of strokes and patent foramen ovales (PFOs). PFOs are small congenital connections between the right and left atrial chambers of the heart that persist in ~25% of adults. In the fetus, this connection is a vital conduit that allows the immature, nonfunctioning lungs to be bypassed. In adults, this connection closes, and the lungs become not just the oxygenator of the body, but also serve as a filter for little clots and debris that frequent the venous circulation.
As our ability to see this connection developed with the advent of ultrasound, clinicians began to report cases of blood clots transiting through this connection from the right heart to the left heart. This is a problem because the left heart pumps 1/5th of its blood volume to the brain, and so a cerebral embolism (or stroke) is the feared complication of clots that find their way into the left heart. When a much higher proportion of patients than expected (40%) with uncertain causes of stroke were found to have a PFO, clinicians suspected these conduits as the cause of the stroke.
In response, cardiologists began closing these connections via catheters that delivered ingenious little double umbrellas to the heart. Unfortunately, as the experience with these devices closures grew, it turned out that there were possibly other causes of stroke in this population. Closing a PFO in someone who had a stroke because of a certain type of arrhythmia of the heart made the device company that sold the closure device happy, but did precious little else. Three randomized control trials comparing PFO closure with medical therapy were carried out to test the prevailing strategy of PFO closures – CLOSURE 1, PC, and RESPECT.
All three were negative trials. The prevailing wisdom suddenly became that there was no evidence that PFO closures worked in preventing recurrent strokes. The American Academy of Neurology even put out a position paper arguing against PFO closures. Yet, I read the same trials and arrived at very different conclusions. There were major issues with the trials that explained the negative results to me. The CLOSURE 1, and PC trials included patients with Transient Ischemic attacks (TIAs). For those who don’t know, TIAs are brief neurologic episodes that don’t last long enough to be considered a stroke. Numbness and tingling on one side of the face could be a TIA, or it could be nothing. Subjectivity reigns even among neurologists about this diagnosis, and it seems imminently plausible that many of the patients enrolled in these two trials had PFO closures for events that may not have been neurologic. These first two trials also included patients with lacunar strokes – small strokes that could be a result of hypertension, high cholesterol or advanced age rather than embolism of a clot. The last trial of this initial set of three studies -the RESPECT trial – sought to rectify the errors of its predecessors by excluding TIAs, and lacunar strokes. They also sought to analyze the risk of stroke as it related to the size of the PFO. Not all PFOs are equal – some are very small defects that only allow a minimal passage of blood, while others are much larger conduits. The reasonable presumption was that most of the benefit to closing PFOs came from closing the large PFOs – the subset analysis would allow an analysis of this potential heterogenous treatment effect. Strictly speaking, the RESPECT trial was a negative trial – another disappointment. No statistically significant difference in was found between the PFO closure group and medical therapy group.
There were half as many strokes in the closure groups – 9 strokes in the PFO closure group, vs. 16 strokes in the medical therapy group. But the trial was reported as negative because when comparing those assigned to the closure device vs. medical therapy, the hazard ratio crossed 1, and the p value was a little over the magical and somewhat arbitrary 0.05 threshold. The analysis also took the form of the conventional ‘Intention To Treat (ITT)’ where patients are analyzed based on their initial assignment rather than the treatment that was ultimately received. While this is statistically pure, it does not account for the fact that 4 patients who suffered a stroke after being randomized to a PFO closure device had a stroke while waiting to receive the device.
Effectively, the four strokes were ‘blamed’ on the PFO device.

RESPECT Trial Outcomes
One common explanation for analyzing by ITT is that ITT may best simulate the real world effect size when clinicians assign patients to a certain treatment. While that is possible, it could also be that clinicians respond to this data by placing closure devices more expeditiously. Not counting the four strokes that happened before the closure device was placed, (also called as treated, or the per protocol analysis) the numbers (5 vs. 16) did reach statistical significance. Also not reflected in the yes/no world of clinical trial reporting in journals was the fact that of the 5 patients with a device that had a stroke, only one was considered moderate, or massive, compared to 9 in the medical therapy arm. Finally, the subgroup analysis of the size of shunt, confirmed that the larger the shunt size, the higher the risk of recurrent stroke, and the greater the benefit of closure.
The other important point was that while closing the PFO may be an effective strategy to prevent recurrent strokes, blood thinners like coumadin to prevent blood clots from forming in the first place were another option supported by prior observational data. The three initial RCTs had allowed participating investigators free reign with regards to choice of medical therapy in the medical arm – some chose antiplatelet drugs and others chose anticoagulation. It seemed very unlikely that closure devices could outperform systemic anticoagulation – yet another possible reason for the lack of effect of closure devices seen.
To me, the RCTs were helpful in confirming who likely had a small or no benefit to closure- patients with TIAs/lacunar strokes and small PFOs. I wrote about the saga – and concluded that PFO closures were a good option in patients with large PFOs who had suffered a stroke and were loathe to be on blood thinners.
Much of the neurology community and many EBM experts ignored the subtext and focused on the lack of statistical significance. Luckily, the clues readily apparent to me were also apparent to folks far more significant than me. The longer term results of the RESPECT trial was enough to convince an FDA panel that despite the lack of statistical significance, there was a clear signal for clinical significance to merit approval of PFO closures for preventing cryptogenic stroke after a careful evaluation to rule out other causes of stroke.
But since we live in a world where no story is settled until an RCT is positive, unbeknownst to me there were additional trials taking place to prove to the god of epistemology (currently a part-time oncologist in Oregon) that PFO closure devices were indeed beneficial. In the Sep 14, 2017 issue of the New England Journal of Medicine – three RCTs were published. One of the trials was a long term follow up of RESPECT that now showed a statistically significant benefit of PFO closures. The two other trials were the GORE-REDUCE, and the GORE-CLOSE trial. These latter trials enrolled mostly patients with large PFOs and strokes. The GORE-CLOSE trial randomized patients to antiplatelet therapy only, PFO closure, as well as oral anticoagulation, while the GORE-REDUCE trial compared PFO closures to antiplatelet therapy. Clearly the investigators had learned from the prior missteps, by focusing on larger PFOs, sidestepping the subjective nature of TIAs, and mandating a treatment arm that consisted of antiplatelet therapy only. Apparently there was clinical equipoise to do this.
Nonsense.
The RESPECT trial should have confirmed to those paying attention that patients presenting with a stroke and a large PFO should NOT be treated with antiplatelets only. The only folks with equipoise here were those that were logically challenged or those that allowed EBM to suppress what should have been intuitive. There was a price to pay for suspending logic. In the GORE-CLOSE trial, which at least allowed for an anticoagulation arm, 14 patients in the antiplatelet group had a stroke, compared to zero in the PFO closure arm, and two in the oral anticoagulation arm. In the GORE-REDUCE trial 12 patients had a stroke in the antiplatelet only arm, compared to six in the closure group.
So the positive signals gleaned from the original ‘negative’ RCTs had been on the mark. The perfect balance of the known covariates in the trials had provided no protection against an erroneous inference. As the subsequent positive trials demonstrated, the initial analysis that got it wrong wasn’t derailed because of unknown confounders, known confounders, poor randomization, or inaccurate average treatment effects. It was a failure to ask why.
Bertrand’s Chicken
As physicians, it has become our practice to bring experience and personal observations together to allow us to doctor patients. The fallibility of eminence and personal observations lead us to the realm of hypothesis testing and RCTs. The idea was that adding this interlocutor would bring us closer to the truth, or at least result in fewer dead ends. In reality we only ever had the illusion of a more certain truth. It turns out that regurgitating the weekly New England Journal of Medicine conclusions fortified with p values may have been far less valuable than I thought as Ioannidis and others document.
Bertrand Russell, British philosopher, logician and mathematician wrote about these very same difficulties as it relates to the simple chicken. The chicken bases what he expects on his experience. Every day the farmer shows up and food appears. To the chicken what happens tomorrow is based on the sum total experience of all the days before. The chicken fully expects the farmer to come tomorrow with food because that has happened every prior day of existence. Except tomorrow is the day the farmer arrives and wrings its neck. The chicken got it all wrong. Before scoffing too much at the chicken’s primitive way of thinking, consider that Russell started his chapter on the problems inherent with inductive inference by asking us to consider why the sun should rise tomorrow. If your answer is because it has risen every day prior, you are guilty of chicken-headed thinking.
Unfortunately RCTs and null hypothesis testing would serve to advance neither the chicken’s search for the truth or ours, unless we ask questions that lead us to cause. For this it is important to know why. Understanding cause has little to do with what happens. We reduce ourselves to chicken-headed thinking if our efforts are directed at what happened. Chickens know what happened, what beasts of nature fail to understand is why things happen. The analogy in medicine is to observe the initial PFO closure trials, note no statistically significant difference, and go no further. This is chicken-headed. Dive deeper, understand why the inclusion of patients with TIAs may have resulted in patients without cerebral embolic events being included. Don’t dogmatically attribute strokes to PFO closure devices if they happen prior to the device being implanted. And please don’t smugly discount the observations of thrombi transiting through PFOs into the left side of the heart, and the subsequent stroke that happened as true, true and unrelated.
Yes, biological models (leeches for bad humors) have been wrong, but don’t discount all future proposed models out of hand because of it. By all means allow data in its many forms (case series, anecdotes, parallel control RCTs, adaptive design RCTs, etc. ) to modify, sharpen, or even discard a model. But don’t give up on models, don’t give up on seeking out why, and please don’t listen to this guy –
The common refrain from some quarters is that statistics has come a long way from Fisher’s t-test and the basic parallel controlled randomized control trial. Different trial designs as well as methods to analyze randomize control trials post-hoc to account for some of the weakness discussed abound. Bayesian statistics seeks to incorporate various priors – optimistic, neutral, skeptical – to arrive at a range of posterior probabilities. I am sympathetic to the number crunching whiz kids earnestly trying to help us arrive at scientific truth by better parsing what the data tells us. But it is a mistake to think that the heavy lifting needed to understand the recent randomized control trial comparing ablation for atrial fibrillation to placebo that had 30% of patients crossover to the treatment arm will come via instrumental variables or something that sounds even sexier. The closest we can hope to get to the truth at any point in time will lie somewhere within the community of physicians managing patients with atrial fibrillation because they are best able to provide the context any one study needs. And while this certainly introduces bias and subjectivity into the interpretation of results, it is neither possible or wise to eliminate this.
The move to strip biases, to fight instincts, to discard knowledge at times painstakingly acquired outside of the hallowed RCT construct is ultimately misguided. The current crisis of evidence will not be soothed by analyzing data better, or by stripping the biases of clinicians. The words of Bartlett as he explained his reasoning for proceeding with the ECMO RCT should be chilling: ” we felt compelled… we knew that 90% of patients assigned to the control group would die..” It should have been enough for Bartlett to convince his peers in the intensive care unit of the value of what he was doing. Statisticians, hospital administrators, and insurance carriers have no business demanding ‘higher’ levels of evidence here, in part because they are woefully unqualified to evaluate any evidence that’s even compelled to be produced. The creation of clinical equipoise by statisticians who can never be certain of anything is a self defeating proposition. Causal inference comes from searching for the why of it. If 200/10000 patients exposed to a certain meteorite are stricken with cancer, and only 10/10000 patients not exposed get the same cancer, the question that should consume the clinician and researcher is why this happened. Why didn’t all 10000 patients in the affected neighborhood get cancer. What could the underlying mechanism be? Is there an activator of some kind common to the 200 unfortunate patients? Do they share some genetic code that predisposes them to being stricken? Not asking these questions, or proceeding with blinders on to test random treatments in a hundred RCTs lowers us to the level of chickens. The less we think as chickens, the better.
Anish Koka (@anish_koka) is a cardiologist in private practice in Philadelphia. Many thanks to those who provided comments including David Norris (@davidcnorrismd), Saurabh Jha (@roguerad), and John Tucker (@JohnTuckerPhD). Insights/examples gleaned from the wonderful works of Stephen Senn (@stephensenn ), William Briggs/Uncertainty. Errors in translation of concepts are solely the fault of @anish_koka.
Categories: Uncategorized








Very good, Anish. Thank you.
As soon as Monty Hall opens a door showing a goat, the problem changes completely. As you and Bayes say, don’t throw away knowledge acquired after the problem was set up!