
By ANISH KOKA
The year was 1965, the place was Boston Children’s and a surgery resident named Robert Bartlett took his turn at the bedside of a just born baby unable to breathe. This particular baby couldn’t breathe because of a hole in the diaphragm that had allowed the intestines to travel up into the thoracic cage, and prevent normal development of the lungs. In 1965, Robert Bartlett was engaged in the cutting edge treatment of the time – squeeze a bag that forced oxygenated air into tiny lungs and hope there was enough functioning lung tissue to participate in gas exchange to allow the body to get the oxygen it needed. Bartlett persisted in ‘bagging’ the child for 2 days. As was frequently the case, the treatments proved futile and the baby died.
The strange part of the syndrome that had come to be known as congenital diaphragmatic hernia was that repairing the defect and putting the intestines back where they belonged was not necessarily curative. The clues to what was happening lay in autopsy studies that demonstrated arrested maturation of lung tissue in both compressed and uncompressed lung. Some systemic process beyond simple compression of one lung must be operative. It turns out that these little babies were blue because their bodies were shunting blood away from the immature lungs through vascular connections that normally close off after birth. Add abnormally high pressures in the lungs and you have a perfect physiologic storm that was not compatible with life.
Pondering the problem, Bartlett wondered if there was a way to artificially do what the lungs were supposed to do – oxygenate. Twelve years later in 1977, while most pediatric intensive care units were still figuring out how to ventilate babies, a team lead by Bartlett was using jerry rigged chest tube catheters to bypass the lungs of babies failing the standard treatments of the day. In a series of reports that followed, Bartlett described the technique his team used in babies that heretofore had a mortality rate of 90%. A home made catheter was placed in the internal jugular vein and pumped across an artificial membrane that oxygenated blood before it was returned via a catheter to the carotid artery. The usual hiccups ensued. The animal models didn’t adequately model the challenges of placing babies on what has come to be known as ECMO (Extra Corporeal Membrane Oxygenation).
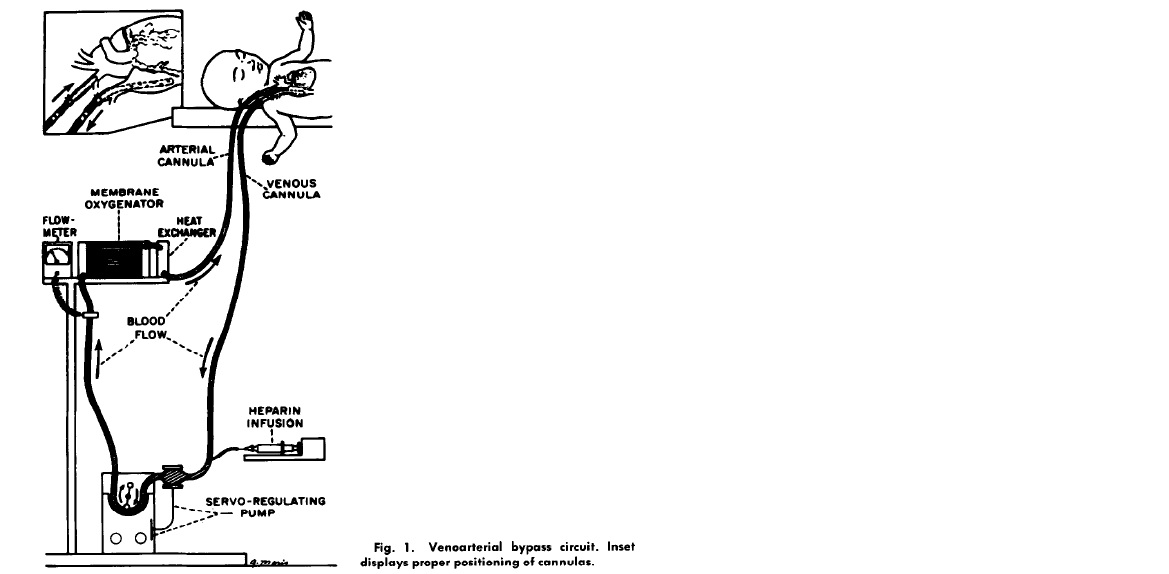
Patient 1 developed a severely low platelet count, hemorrhaged into the brain and died. Patient 2 survived but was on a ventilator for 7 weeks. Patient 3 developed progressive pulmonary hypertension and died. Patient 4 died because of misplacement of one of the ECMO catheters.
The team improved, and mortality in this moribund population improved to 20%. The pediatric journals of the day refused to publish the data because they felt ECMO for neonates was irresponsible. Once published, the neonatology community came out in force against ECMO, and some penned editorials implying the children only became supremely ill because Bartlett’s team was incompetent. The team persisted, as is anyone that is driven by the desperate need of patients. None of this should be surprising. The constant battle between skeptics and proponents is a recurring theme known to anyone with even a limited understanding of medical history. But this is where the story goes off the rails.
One of the fundamental tenets of Evidence Based Medicine (EBM) that had been established was that no therapy could be known to be beneficial unless it was proven so in a Randomized Control Trial (RCT). The Michigan group ultimately published their phase 1 experience – a collection of the first 55 patients they treated with ECMO. The results were remarkable. In a group of patients that were failing all medical therapy that was known at the time, with an expected mortality of 90%, 28/40 (70%) children with a birth weight over 2kg survived. But, it didn’t matter. Bartlett felt compelled to form an RCT because..
“none our colleagues — neonatology staff, referring physicians, other prominent neonatologists, other prominent life support researchers, hospital administrators, insurance carriers, the NIH study sections which reviewed our grant applications, the editors which reviewed our publications, and the statisticians which reviewed our claims and methods – believed that ECMO had been tested let alone proven in neonatal respiratory failure…
we ourselves felt compelled to evaulate the new technique in a way that our colleagues listed above acknowledge and respect…
We knew that 90% of patients assigned to the control group would die with conventional therapy..”
We hear about nefarious incentives pushing physicians to do more, but we hear next to nothing about incentives of payers and administrators to promote doing less. What better time for hospital administrators and payers to invoke lack of proof than when sitting across the table from physicians asking for support for a procedure that promised to increase costs manifold. A quick death of a baby is tragic. But to those who are paying, its also cheap.
Bartlett went ahead with the randomized control trial he felt compelled to perform to convince the wider community. He attempted to get around the ethical quandary by having a randomization protocol that would ensure far fewer than 50% of patients randomized would end up in the control arm. The study was a randomized ‘play the winner approach’ that had been described but never before used in a clinical trial. Using a balls-in-urn model, the randomization consisted of drawing a treatment allocation ball from an urn at random, with replacement. Initially the urn contained one conventional therapy ball and one ECMO ball. The protocol called for the addition of one ECMO ball each time a patient survived on ECMO or a patient died with conventional therapy. Similarly, it called for the addition of a conventional therapy ball for survival on conventional therapy or death on ECMO. The stopping rule – determined in advance – was to stop the randomization whenever ten balls of one type were added.
The first patient was randomly assigned to ECMO and survived. The next random assignment was to conventional treatment and died. The third patient assigned to ECMO survived. The odds heavily favored ECMO, and the next nine patients were randomized to ECMO. All the patients randomized to ECMO survived.
So the first adaptive trial design used in clinical practice was wildly positive for the new treatment proffered. Unsurprisingly, the community of skeptics remained unmoved. The arguments were predictable. The randomization was atypical. The study was biased to show the therapy would succeed. The control arm only consisted of one patient! At best, nothing definitive could be said. Another, more conventional randomized control trial was needed.
And so another group duly performed an RCT. This second trial was designed to satisfy the EBM orthodoxy by assigning an approximately equal number of patients to control arm or ECMO. The study was still designed to limit the number of patients assigned to the inferior arm by limiting the 50:50 randomization until the 4th death occurred in either group. At that point, randomization would cease and all subsequent patients would be enrolled in the group with less than 4 deaths. The first 19 patients were randomly assigned to conventional therapy or ECMO therapy. Nine patients received ECMO, and all survived. Ten patients received conventional therapy – six survived and four died. After the fourth death, randomization ceased and the next 20 patients were assigned to ECMO treatments. Of these 20, 19 survived, 1 died. It bears repeating that in a group of patients that were included in this trial because mortality with conventional therapy was believed to be 85%, 19/20 survived in the ECMO arm. Even more troubling, four babies died being randomized to the control arm. The medical community, buoyed by the need to generate ‘gold standard’ evidence could not help but randomize dying babies to a control arm to convince the statistical gods. The gods of EBM are like the ancient Mayan gods – both require human sacrifice.
Driving while Drunk
EBM was intoxicating. For clinicians, the application of statistics to data was like a magic truth machine. Feed data into this machine, and beautiful binary answers emerged. The era of EBM fueled an explosion of data being peer reviewed and published in an uncountable number of journals. These simple conclusions – Coffee is bad! Moderate alcohol consumption is bad!- were then amplified by the lay media and bundled as ‘facts’ that the Starbucks coffee drinking populace devoured. It is seldom obvious to the drunken driver how often they stray into opposing traffic – and while it took some time, it eventually became obvious that EBM had a problem staying in the right lane.
An EBM fact was apparently not like discovering the world was was not flat. One year coffee was good, the next year coffee was bad. The public seemed not to catch on, but others did. One of the first to point out systematic issues with EBM was an unassuming Infectious Disease trained epidemiologist and biostatistician named John Ioannidis. In 2005, he penned a provocative article that would go onto become one of the most cited papers ever that suggested most published research findings were false. The thing is that he wasn’t exaggerating.
In the current world of clinical research we reside in, I develop a hypothesis that activation of the Koka receptor on the heart with drug KokaCabana will reduce mortality in heart failure patients. The next step is to run a clinical trial comparing it to a placebo and counting mortality in the two arms. At the end of the trial fewer deaths are seen in the KokaCabana arm. The question that faces us is if fewer deaths was a play of chance or if KokaCabana actually works. This question is turned over to statisticians who for the most past rely heavily on the work on Sir Ronald Fisher, a British statistician born in London in 1890. Fisher posited the idea that experiments have a null hypothesis that should be rejected by observations that are unlikely. To quantify how unlikely the events are to occur, Fisher described the famous p value as the tail area under a frequency distribution that would exist if the null hypothesis was true. A small p value means a very rare thing has been observed, or the null hypothesis is not true.

KokaCabana needs a small p value – billions of dollars hang in the balance. The accepted threshold for significance for p values is 0.05. A value of 0.04 and Egyptian Pharaoh’s would be envious of the riches Dr. Koka will acquire. A value of 0.06 and KokaCabana will be judged to be a sham, the equivalent of a worthless sugar pill.
That there could be a physiologic threshold to differentiate useful from useless should seem preposterous on its own. Unfortunately, the problem extends well beyond the 0.05 cliff of truth. The general premise that a p of 0.05 provides some assurance of a real effect is incorrect and was never intended to do so by the man who originally described p values. What we are desperate to know is the probability our hypothesis (h) is true given the evidence provided (e), but our p value instead gives us the probability this particular evidence is observed (e) given a certain hypothesis (h).
In brief: Probability (h | e) ≠ Probability ( e | h)
In more simple terms: Probability ( 4 legs | dog ) ≠ Probability ( dog | 4 legs )
Given a dog, the probability of 4 legs is very high. Given 4 legs, the probability of a dog is not very high. The trial results are akin to being given a result of 4 legs. Proving the 4 legged creature is a dog requires things like context. It helps to be told you’re in a dog park for instance. That context is part of what can be termed the prior probability. The prior is what allows one to travel from evidence to hypothesis.
Probability (h | e) ~ Probability ( e | h) x Probability (prior)
Somewhere along the way the importance of context – the importance of the prior probability – was lost. The evidence based movement was supposed to be the great equalizer that leveled the playing field between the experts and their biases and everyone else. You didn’t need to be an interventional cardiologist to decide if a device used in patients with cardiogenic shock was effective or not. A family practice physician who hasn’t stepped in a cardiac intensive care unit to manage a patient with heart failure only needs the published randomized control trials on the subject to know if the device for cardiogenic shock is effective. The problem of course is the prior. Whose prior should we trust?
Not paying attention to the prior increases the chances of committing the fallacy of the transposed conditional – mistaking the probability of the data given the proposed hypothesis with the probability of the hypothesis given the data. And so it was that the evidence based movement that sought to embrace numeracy to build a stronger foundation turns out to have a river running underneath it. Think sink hole, not Hoover Dam.
John Ioannidis even attempted to quantify how changing prestudy odds changes the likelihood a study actually tells you what you think it does. The different colors are used to reflect differing levels of bias. The higher the pretest odds, the higher the likelihood of a real effect. The higher the bias, the lower the likelihood a real effect is found. Also implicated as a source of false positive studies are multiple investigators working on the same research question. Chance dictates one of the studies is positive. The focus is on the one positive study, not the many negative — and thats if the negative studies are even published.


It is interesting that Ioannidis chooses to solve the problem that started with an attempt to quantify certainty by attempting to quantify uncertainty. The graphs are pretty and serve to make the point that evidence is subject to context and bias, but both are markedly subjective and make possible a wide range of outcomes. Bias on the part of researchers has at times increased the chances a real effect is found. As an outsider it is hard to know what drives investigator bias. Many times third parties assume the worst – financial, academic promotion, etc. Skeptics of the day presumed some type of bias that didn’t allow the Bartlett team to see things clearly, and demanded a more conventional trial in which 4 babies died in the control arm.
Interestingly, Ioannidis’ solutions feel imprisoned by the very frame that created the problem.
” large scale studies should be targeted for research questions where the pretest probability is already high.. “
” greater understanding of [pretest odds ] is needed “
“large studies with minimal bias should be performed on research findings that are relatively established “
Yet, large scale studies are particularly prone to demonstrating statistically significant, yet small clinically insignificant findings. A greater understanding of pretest odds is best acquired by those with the most bias (otherwise known as expertise). Lastly, in the zeal to overturn established practices, consider that there may be good reason practices are established.
The Lindy effect is a term popularized by the mathematician-philosopher-best selling author, Nassim Nicholas Taleb used to predict robustness. Things that have been in existence for a long period of time can be considered more robust, more likely to endure than things that have not passed the test of time. As an example – the recent controversy about the value of opening stenosed coronary arteries stems from a novel first of its kind 200 patient study that was essentially negative. While there are important lessons to learn from the trial, clinicians as a group have been reluctant to allow one 200 patient trial to completely reverse a concept that has been operative for for forty years. This may not be irrational. Forty years of robustness where numerous other treatments for angina have come and gone may very well have real meaning. In Lindy terms, past survival predicts future survival – this predicts arteries will be opened in one fashion or another for at least the next 40 years.
So EBM as practiced and widely accepted struggles with causal inference. Regurgitating the most recent conclusion from the randomized control trial in the New England Journal of Medicine means you are more likely to be participating in the fallacy of the transposed conditional than you are to be speaking truth. It turns out that finding cause has to do with why the numbers are produced. The numbers – no matter how cleverly you manipulate them – don’t have the answers you seek.
Anish Koka is a cardiologist based in Pennsylvania
Categories: Uncategorized








Tx for reading steve! Love the comments. The value of that ‘old guy’ seems to be on the wane. Many physicians discuss the problems with experts – and openly ? If they’re needed in this era because they’re biased. Their bias is of course needed to interpret the trial.. :). I’m glad it still works the way it should where you are. Any cardiology openings where you are?
“the most recent conclusion from the randomized control trial in the New England Journal of Medicine”
Are people where you work really practicing that way? Granted, the department I chair is not in the big city, but we certainly don’t work that way. The latest paper? Great! How does it compare to prior work and how does it compare with what we see in our day to day practice. That is what I think of as EBM. You look at all of the evidence, not just the last paper. When did it mutate into that? If that is how the people where you work really do practice and it is really widespread, then I guess I should take this just a bit more seriously, but it really doesn’t seem that much different than when I was rounding as an intern back at Penn decades ago. You scored points by citing the latest paper. There was always someone who wanted to immediately jump on that latest paper and change everything. And if we were lucky, there was some older guy who said wait a minute, does that really make sense?
(Also, since when did papers about coffee equate to EBM? To any kind of M? Maybe, maybe in the popular press, but certainly not, I hope, for practicing docs.)
Steve