Evidence is mounting that publication in a peer-reviewed medical journal does not guarantee a study’s validity. Many studies of health care effectiveness do not show the cause-and-effect relationships that they claim. They have faulty research designs. Mistaken conclusions later reported in the news media can lead to wrong-headed policies and confusion among policy makers, scientists, and the public. Unfortunately, little guidance exists to help distinguish good study designs from bad ones, the central goal of this article.
There have been major reversals of study findings in recent years. Consider the risks and benefits of postmenopausal hormone replacement therapy (HRT). In the 1950s, epidemiological studies suggested higher doses of HRT might cause harm, particularly cancer of the uterus. In subsequent decades, new studies emphasized the many possible benefits of HRT, particularly its protective effects on heart disease — the leading killer of North American women. The uncritical publicity surrounding these studies was so persuasive that by the 1990s, about half the postmenopausal women in the United States were taking HRT, and physicians were chastised for under-prescribing it. Yet in 2003, the largest randomized controlled trial (RCT) of HRT among postmenopausal women found small increases in breast cancer and increased risks of heart attacks and strokes, largely offsetting any benefits such as fracture reduction.
The reason these studies contradicted each other had less to do with the effects of HRT than the difference in study designs, particularly whether they included comparable control groups and data on preintervention trends. In the HRT case, health-conscious women who chose to take HRT for health benefits differed from those who did not — for reasons of choice, affordability, or pre-existing good health. Thus, although most observational studies showed a “benefit” associated with taking HRT, findings were undermined because the study groups were not comparable. These fundamental nuances were not reported in the news media.
Another pattern in the evolution of science is that early studies of new treatments tend to show the most dramatic, positive health effects, and these effects diminish or disappear as more rigorous and larger studies are conducted. As these positive effects decrease, harmful side effects emerge. Yet the exaggerated early studies, which by design tend to inflate benefits and underestimate harms, have the most influence.
Rigorous design is also essential for studying health policies, which essentially are huge real-world experiments. Such policies, which may affect tens of millions of people, include insurance plans with very high patient deductible costs or Medicare’s new economic penalties levied against hospitals for “preventable” adverse events. We know little about the risks, costs, or benefits of such policies, particularly for the poor and the sick. Indeed, the most credible literature syntheses conducted under the auspices of the international Cochrane Collaboration commonly exclude from evidence 50% to 75% of published studies because they do not meet basic research design standards required to yield trustworthy conclusions (eg, lack of evidence for policies that pay physicians to improve quality of medical care).
This article focuses on a fundamental question: which types of health care studies are most trustworthy? That is, which study designs are most immune to the many biases and alternative explanations that may produce unreliable results? The key question is whether the health “effects” of interventions — such as drugs, technologies, or health and safety programs — are different from what would have happened anyway (ie, what happened to a control group). Our analysis is based on more than 75 years of proven research design principles in the social sciences that have been largely ignored in the health sciences. These simple principles show what is likely to reduce biases and systematic errors. We will describe weak and strong research designs that attempt to control for these biases. Those examples, illustrated with simple graphics, will emphasize 3 overarching principles:
1. No study is perfect. Even the most rigorous research design can be compromised by inaccurate measures and analysis, unrepresentative populations, or even bad luck (“chance”). But we will show that most problems of bias are caused by weak designs yielding exaggerated effects.
2. “You can’t fix by analysis what you bungled by design” . Research design is too often neglected, and strenuous statistical machinations are then needed to “adjust for” irreconcilable differences
3. Publishing innovative but severely biased studies can do more harm than good. Sometimes researchers may publish overly definitive conclusions using unreliable study designs, reasoning that it is better to have unreliable data than no data at all and that the natural progression of science will eventually sort things out. We do not agree. We will show how single, flawed studies, combined with widespread news media attention and advocacy by special interests, can lead to ineffective or unsafe policies.
The case examples in this article describe how some of the most common biases and study designs affect research on important health policies and interventions, such as comparative effectiveness of various medical treatments, cost-containment policies, and health information technology.
The examples include visual illustrations of common biases that compromise a study’s results, weak and strong design alternatives, and the lasting effects of dramatic but flawed early studies. Generally, systematic literature reviews provide more conservative and trustworthy evidence than any single study, and conclusions of such reviews of the broad evidence will also be used to supplement the results of a strongly designed study. Finally, we illustrate the impacts of the studies on the news media, medicine, and policy.
Selection biases may be the most ubiquitous threat to the trustworthiness of health research. Selection bias occurs when differences between treatment recipients and nonrecipients or control groups (based on such factors as income, race, or health) may be the true cause of an observed health effect rather the treatment or policy itself.
Healthy user bias is a type of selection bias that occurs when investigators fail to account for the fact that individuals who are more health conscious and actively seek treatment are generally destined to be healthier than those who do not. This difference can make it falsely appear that a drug or policy improves health when it is simply the healthy user who deserves the credit.
One well-known example is the national campaign in the United States to universally vaccinate all elderly people against the flu. The goal is to reduce the most devastating complications of flu, death and hospitalizations for pneumonia. No one disputes the idea that flu vaccines reduce the occurrence and symptoms of flu, but the national campaign was based on the assumption that the vaccines could also reduce the number of pneumonia-related hospital admissions and deaths. This assumption was based on dozens of cohort studies that compared what happened to older patients who chose to get a flu vaccination with what happened to older patients who did not or could not.
These cohort studies, however, did not account for healthy user bias. For example, a study of 3,415 people with pneumonia (and at high risk for flu and its complications) illustrated that elderly people who received a flu vaccine were more than 7 times as likely to also receive the pneumococcal vaccine as elderly people who did not receive a flu vaccine (Figure 1). They were also more likely to be physically independent, have quit smoking, and to be taking statins, a medication that improves survival of patients with heart disease, diabetes, and other conditions and prevents heart attacks and strokes among the elderly. In short, elderly people who got the flu vaccine already were healthier, more active, and received more treatment than those who did not and so had lower rates of flu-related hospitalization and death during the study period.

Healthy user bias is a common threat to research, especially in studies of any intervention where the individual patient can seek out health care and choose to be immunized, screened, or treated. This same type of bias is largely responsible for all the many health “benefits” attributed to taking multivitamins, antioxidants such as vitamin C or vitamin E, modest amounts of red wine, vegetarian or low red meat diets, fish oil supplements, chelation therapy, and so on. Most of these interventions, when subjected to randomized trials, show no particular benefits and, sometimes, even harm.
Weak research designs that do not control for healthy user bias
One of the most common study designs examining the risks and benefits of drugs and other interventions is the epidemiological cohort design, which compares death and disease rates of patients who receive a treatment with the rates of patients who do not. Although seemingly straightforward, this design often fails to account for healthy user bias, especially in studies of health care benefits.
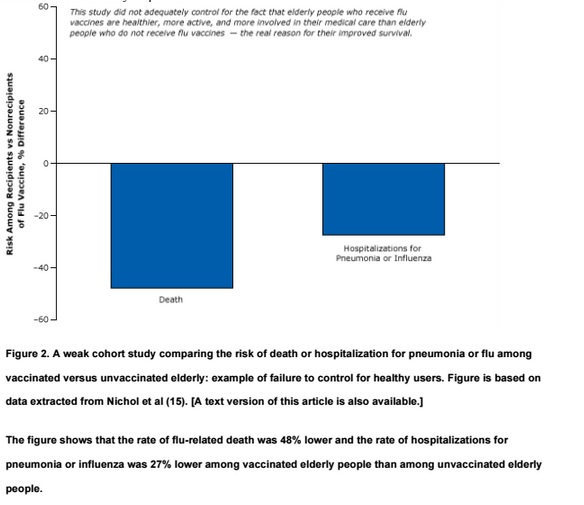
For example, one of many weak cohort studies purported to show that flu vaccines reduce mortality in the elderly (Figure 2). This study, which was widely reported in the news media and influenced policy, found significant differences in the rate of flu-related deaths and hospitalizations among the vaccinated elderly compared with their unvaccinated peers. Although it controlled for certain easy-to-measure differences between the 2 groups, such as age, sex, and diabetes, it did not account for other more difficult-to-measure “healthy user” factors that affect the well-being of the elderly, such as their socioeconomic status, diet, exercise, and adherence to medical treatments and advice.
The cohort design has long been a staple in studies of treatment outcomes. Because such studies often do not account for people’s pre-existing health practices, they tend to inflate or exaggerate the benefits of treatments (eg, the flu vaccine) while downplaying harms (eg, HRT). In general, we should be skeptical about the benefits of health care interventions (such as the use of drugs or vaccines) reported in cohort studies. On the other hand, the findings of cohort studies related to harms and side effects of medications are often more credible because patients and their physicians do not “choose” to be harmed and tend to avoid known harms. Also, the same healthier people are less likely to have side effects or quit medications. Finally, harms and complications are far rarer than the possible benefits. For instance, whereas the benefits of the flu vaccine can be shown in studies of a few thousand participants, hundreds of thousands of participants might be needed to demonstrate the vaccine’s harms or side effects. For example, Guillain-Barré syndrome occurs in 1 in 500,000 people who receive the flu vaccine.
Strong research designs that do control for healthy user bias
Epidemiological studies that have led to national campaigns have been overturned by subsequent stronger studies. One landmark study found that the fourfold increase in the percentage of elderly people in the United States receiving a flu vaccine during 3 decades (1968–1998) was accompanied not by a decrease, but an increase, in hospitalizations and deaths. (Figure 3 in http://dx.doi.org/10.1001/archinte.165.3.265 PubMed.) This does not mean the vaccination is causing flu-related deaths or pneumonia. It means the population is getting a bit older and a bit sicker during flu season and the vaccine has little effect among the elderly.
This study did not have the healthy user bias found in the previous study because it did not compare health-conscious elderly people who chose to get the flu vaccine with their sicker counterparts who chose not to. Instead, it evaluated whether a marked rise in flu vaccines resulted in fewer deaths over time in the entire population.
This study, using a strong design with 30-year trend data, demonstrates the power of pictures — little statistical training is needed to interpret the graph.
A strong, particularly creative study published in 2010 used the same epidemiological design of the weak study illustrated in Figure 2 to show that the so-called benefits of the flu vaccine were statistically equivalent before, during, and after flu season (Figure 3 below). It is not plausible that the vaccine reduced the flu-related death rate in the spring or summer in the absence of the flu, yet we observe the vaccine “protecting” the elderly all year.

The only logical conclusion one can reach from this study is that the benefits during the flu season were simply a result of something other than the effects of flu vaccine — most likely healthy user bias. If fewer vaccinated elders die in the absence of the flu, it is because they are already healthier than unvaccinated elders who may be already too sick to receive a flu vaccination.
Studies with strong research designs that control for selection bias and overturn the exaggerated findings of studies with weak research designs show how weak science in combination with dramatic results can influence the adoption of ineffective health policies. Certainly, greater use of flu vaccine may be reducing the incidence and symptoms of flu. However, the massive national flu vaccination campaign was predicated on reducing the number of flu-related deaths and hospitalizations for pneumonia among the elderly. It could be argued that the funds used for such a campaign could be better spent on developing more effective vaccines or treatments or other methods to reduce the spread of flu.
The news media played a major role in disseminating the misleading results of studies that did not properly take into account the influence of healthy user bias in claims that flu vaccinations could reduce mortality rates and hospitalizations among the elderly. Reuters, for example (Box 1), was unequivocal in its support of a cause-and-effect relationship based on the 2007 report suggesting that flu shots saved lives among the elderly.
Box 1. Reuters Health, October 3, 2007: Flu jab cuts illness and death in elderly
In a study of relatively healthy elderly HMO members, getting a flu shot significantly reduced the odds of being hospitalized with an influenza-related ailment and of dying. . . . “Our study confirms that influenza vaccination is beneficial for reducing hospitalization and death among community-dwelling HMO elderly over a 10-year period,” said the lead author. . . . Flu vaccination reduced the risk of hospitalization for pneumonia or influenza by 27 percent and reduced the risk of death by 48 percent, the report indicates.
Excerpted from this reuters report.
Case 2: Volunteer Selection Bias in Studies of Health Information Technology
This case example describes volunteer selection biases created by studies that use “volunteer” hospital adopters of health information technology (IT) and noncomparable “laggard” controls (the common design in the field). Volunteer hospitals already tend to have more experienced physicians and healthier patients, which may influence health outcomes more than the intervention does.
The flawed results of these sorts of experiments led to federal health IT initiatives, resulting in trillions of dollars spent on unproven and premature adoption of the technologies and few demonstrated health benefits. RCTs failed to replicate the findings on cost savings and lives saved suggested in the poorly designed studies.
Researchers often attempt to evaluate the effects of a health technology by comparing the health of patients whose physicians use the technology with the health of patients whose physicians do not. But if the 2 groups of physicians (or hospitals) are different (eg, older vs younger, high volume vs low volume of services), those differences might account for the difference in patient health, not the technology being studied.
Our national investment in health IT is a case in point. Based in part on an influential report from the RAND think tank , the 2009 federal stimulus law included a requirement that by 2014 physicians should adopt electronic health records (EHRs) with “decision support” (eg, alerts to reduce the number of duplicate or high-dose drugs). If physicians do not achieve this goal, they will be penalized in the form of reduced Medicare reimbursements. The program is a part of national health care reform and costs trillions of dollars in public and private funds. But there is debate about whether health IT can achieve the program’s goals of better health and lower costs. In fact, the RAND think tank has recanted its earlier projections as being overly optimistic and based on less than adequate evidence. Furthermore, recent studies (and even the US Food and Drug Administration) are documenting that health IT can lead to the very medical errors and injuries that it was designed to prevent.
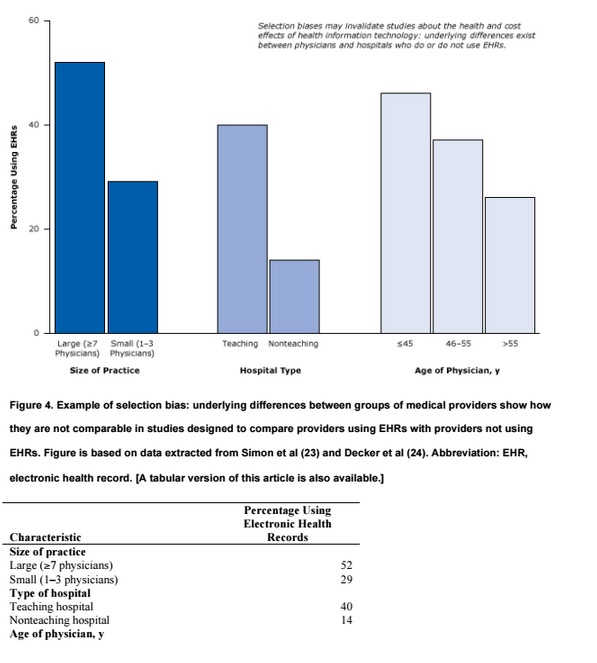
Let’s examine some studies that illustrate how provider selection biases may invalidate studies about the health and cost effects of health IT. Figure 4 illustrates that underlying differences exist between physicians and hospitals who do or do not use EHRs. Large physician practices and teaching hospitals are much more likely to use EHRs than small or solo practices or nonteaching hospitals. Because hospital size and teaching status are predictors of quality of care (with larger hospitals and teaching hospitals predicting higher quality), the 2 factors can create powerful biases that can lead to untrustworthy conclusions. Thus, although studies may associate health IT with better patient health, what they are really pointing out are the differences between older physicians and younger physicians or differences between large physician practices and small physician practices. Such large differences between EHR adopters and nonadopters make it almost impossible to determine the effects of EHRs on health in simple comparative studies. Perhaps as more hospitals adopt EHRs or risk penalties, this type of selection bias may decrease, but that is in itself a testable hypothesis.
Weak cross-sectional research designs that do not control for differences in providers
The following example illustrates how a weak cross-sectional study (a simple correlation between a health IT program and supposed health effects at one point in time) did not account for selection biases and led to exaggerated conclusions about the benefits of health IT . The researchers set out to compare health care sites using EHRs with health care sites using paper records to determine whether patients with diabetes in health care settings with health IT had better health outcomes than patients with diabetes in settings with only paper records (Figure 5).

This weak cross-sectional design would be excluded because of inadequate evidence of the effects of medical services and policies by systematic reviewers adhering to the standards of the international Cochrane Collaboration. The study compared outcomes (eg, blood pressure control) of sites with EHRs and sites without EHRs at one point in time after the introduction of EHRs but did not provide data on such outcomes before the introduction of EHRs; no measure of change was provided. It is virtually impossible to statistically equalize the groups on the hundreds of differences (selection biases) that might have caused differences in blood pressure outcomes; thus, such designs are among the weakest study designs in research attempting to establish cause and effect.
The questionable findings of this study suggested that EHRs might not only improve blood pressure control but also reduce smoking by 30 percentage points (Figure 5). (Strong smoking-cessation programs, such as physician counseling programs, studied in rigorous randomized trials have resulted in a 1% to 2% reduction in smoking.
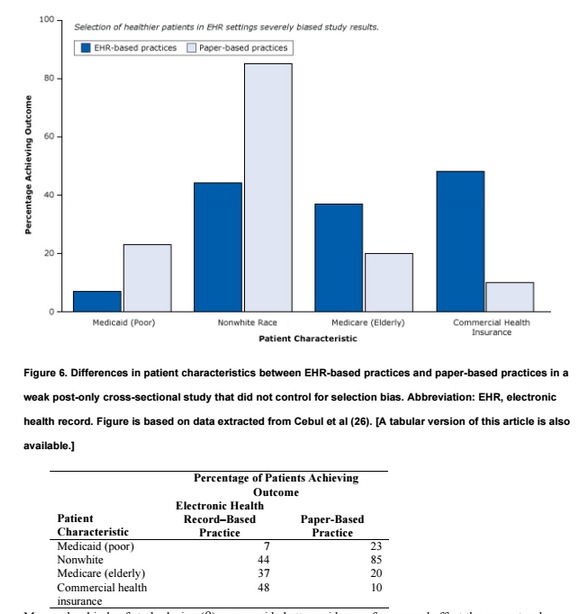
The conclusion of the report — that “the meaningful use of EHRs may improve the quality of care” — is not warranted. As shown in Figure 4, large practices, teaching hospitals, and younger physicians already deliver better care whether or not they use EHRs. Similarly, even in their own study, the authors found that patients in practices with EHRs had better health care to begin with (Figure 6). They tended to be white, less likely to be poor and rely on Medicaid, and more likely to have commercial health insurance — all indicators of a higher socioeconomic status associated with better care that have nothing to do with EHRs.
Many other kinds of study design (9) can provide better evidence of cause and effect than a post-only cross-sectional design can. Nevertheless, the organization that funded the study, the Robert Wood Johnson Foundation, hailed the results nationally (29), and the news media were exuberant with praise (Box 2).
Federal Investment in Electronic Health Records Likely to Reap Returns in Quality of Care, Study Finds
A study . . . involving more than 27,000 adults with diabetes found that those in physician practices using EHRs were significantly more likely to have health care and outcomes that align with accepted standards than those where physicians rely on patient records.
Strong research designs that do control for differences in providers
A diagram shows how randomization often ensures a fair comparison when assessing the effects of an intervention. The intervention begins with a population (eg, patients, health centers). A picture of hand flipping a coin illustrates how randomization often eliminates selection bias. The flip of the coin decides who is randomized to the intervention and who is not. Each arm of the study (intervention and no intervention) produces results, and the results are compared.
This simple design starts with a population (eg, patients, health centers) and uses chance to randomly allocate some centers to the intervention (eg, health IT or not [control]). The researchers then test whether health in the intervention improved more than health in the control. The randomization generally eliminates selection biases, such as facility size or patient age or income. Such designs can reduce bias if they adhere to methodological safeguards, such as blinding patients to their treatment status and randomizing enough patients or centers.
Consider the following randomized control trial involving a state-of-the-art health IT system with decision support in nursing homes (30). By randomizing 29 nursing homes (and 1,118 patients), the researchers controlled for selection biases. The objective of the trial was to examine the effect of computerized warnings about unsafe combinations of drugs to reduce preventable drug-related injuries. The rigorous appraisal of health IT showed that it was ineffective at reducing injuries. Among study patients receiving the health IT intervention, there were 4.0 preventable drug-related injuries per 100 residents per month; among control patients, there were 3.9 preventable drug-related injuries per 100 residents per month (Figure 8). This failure of the health IT intervention was probably due to physicians ignoring most of the warnings, most of which they felt were not relevant to their patients’ health (31). As it often happens in medical research, this strong “negative” study received less attention from the news media than the much weaker but positive studies proclaiming large benefits (5).

A single study, no matter how rigorous, should never be considered definitive. The best evidence of what works in medical science comes from systematic reviews of the entire body of published research by unbiased evaluators — after eliminating the preponderance of weak studies. Such a review of hundreds of health IT studies cited a lack of rigorous evidence (Box 3):
Box 3. Black et al, “The Impact of eHealth on the Quality and Safety of Health Care: A Systematic Overview. PLOS Medicine” (7)
[T]here is a lack of robust research on the risks of implementing these technologies and their cost- effectiveness has yet to be demonstrated, despite being frequently promoted by policymakers and “techno-enthusiasts” as if this was a given.
Advancements in health IT may well achieve the promised cost and quality benefits, but proof of these benefits requires more rigorous appraisal of the technologies than research to date has provided.
Steven Soumerai is Professor of Population Medicine at Harvard Medical School. Douglas Starr is a Professor of Communications at Boston College. Sumit R. Majumdar is a Professor at the University of Alberta.
Categories: Uncategorized








Hi,
Thanks it is good information about health care effectiveness. Nice blog…
Very useful discussion at this point. Thank you.
Pretty soon we are going to have to define health. Eg improvng [health] might increase mortality. We define health as a baseline increase in oxygen consumption. People might feel better, have greater endurance and joie de vivre, yet tip toward inadequate myocardial or brain oxygenation and infarction and hence increased mortality. Ditto with mood therapies for brain function. These might increase risk taking ==> higher mortality. Et al. You get the idea.
In fact “health”–in rigorous definitions–might be precisely defined in many ways. And, therefore, if using an EHR improves some of these healths, it might worsen some of these other healths.
Of course, whimsically, using an EHR might only improve the health of the doctor or his office staff or his hospital or his referring insurers, health plans or their financial bottom lines. Alas, it could simply improve the health of the political class or the economic policy makers of that class.
Why was it necessary to gild the lily here with at least half the body of this article having nothing to do with health IT? Moreover, what, to these authors, would constitute valid study design and deployment of HIT, given that we have thousands of ONC-certified systems in commercial operation, and have for a long time? Are you advocating for pre-deployment certification research governed by FDA criteria? i.e., that EHRs are “medical devices”? That issue has been settled.