Some measures of health care quality and patient safety should be taken with a grain of salt. A few need a spoonful.
In April, a team of Johns Hopkins researchers published an article examining how well a state of Maryland pay-for-performance program measure for dangerous blood clots identified cases that were potentially preventable. In reviewing the clinical records of 157 hospital patients deemed by the state program to have developed these clots — known as deep vein thrombosis and pulmonary embolism — they found that more than 40 percent had been misclassified. The vast majority of these patients had clots that were not truly preventable, such as those associated with central catheters, for which the efficacy of prophylaxis remains unproven.
These misclassified cases of blood clots resulted in potentially $200,000 in lost reimbursement from the state, which penalizes hospitals when the additional treatment costs related to more than 60 preventable harms exceeds established benchmarks.
Why the discrepancies? The state identified cases of these clots using billing data, which utilize the diagnosis codes that medical billing specialists enter on claims. These data, also known as administrative data, lack the detail that would be available in the actual clinical record, considered by many to be the most trusted source for safety and quality measures.
The limitations of billing data, however, are not evident to anyone visiting the state website that reports how hospitals perform on blood clots or any of the Maryland Hospital Acquired Conditions, such as collapsed lung and reopening a surgical site.
This is not an isolated example. Last year, The Johns Hopkins Hospital was criticized by one state agency for high rates of central line-associated bloodstream infections (CLABSI) based on billing data. Yet another agency, which uses the more accepted clinical definition from the Centers for Disease Control and Prevention (CDC), praised the hospital for low rates during the same time period. When the staff went back to look at the clinical records for the patients identified by the billing data as having CLABSI, only 13 percent actually met the CDC definition.
To the average person, there’s little to differentiate one measure from another. Especially on government-sponsored websites, we trust that the measures reported are accurate and have undergone a process of scientific vetting. We don’t expect to see completely conflicting portrayals or even learn that two agencies from the same state display similar quality measures based on different methods.
Assessing the Performance of Performance Measures
These issues don’t surprise those of us who use and research performance metrics in health care. We know that all measures are not created equal. But there needs to be a better way to get that message across to patients, as well as to hospitals, clinicians and payers, so they know how much credence to give them.
Perhaps it’s time that we think about rating the performance of performance measures themselves. Could we score a measure’s validity and reliability on a scale of zero to 100? Issue ratings from one to five stars? Come up with a symbol for the most valid and valuable measures? Let users sort which measures they want to review?
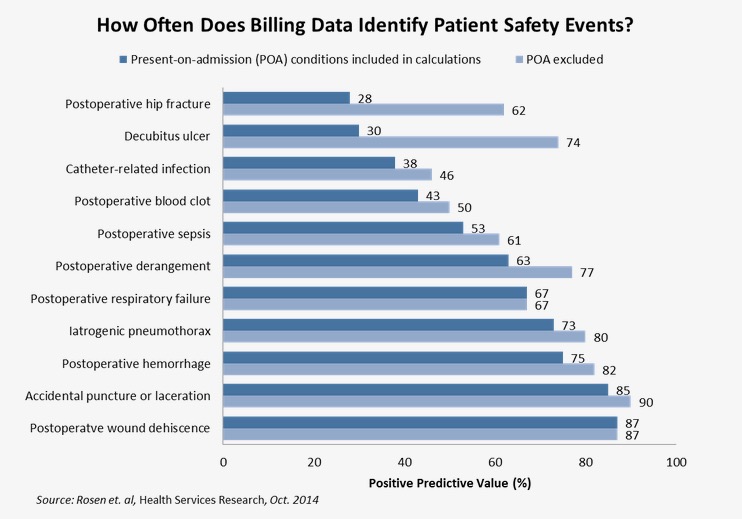
Past research has touched on the wide variation in the performance of quality measures. In a study of the Agency for Healthcare Research and Quality’s Patient Safety Indicators (PSIs), which are based on billing data, researchers reviewed the clinical documentation of Veterans Affairs patients who were determined to have experienced at least one of 12 preventable harms due to their hospital experiences. They found that the positive predictive value — the percentage of cases identified through billing data that were found to be true positives — of these outcome measures ranged from 28 percent (postoperative hip fracture) to 87 percent (postoperative wound dehiscence). Eight of the 12 indicators had predictive values of 67 percent or less.
These false positives result from a host of factors. For example, more than one-half of all postoperative hip fractures in their sample were present before the patient arrived at the hospital for surgery. Other discrepancies resulted from miscoded cases, such as mistakenly coding a clot in the arm as a more serious deep vein thrombosis.
Once patients with present-on-admission conditions were removed from the calculations — now standard in today’s PSI methodology — the positive predictive values increased, with values ranging anywhere from 46 to 90 percent. Yet the usefulness of many measures remains well below what the public should expect.
Imperfect measures don’t necessarily need to be cast away. The gold standard for outcome measures involves collecting data via clinical chart review, but our health care system cannot sustain this time-consuming, expensive process for all measures. Even if less than one-half of the cases flagged by billing data are true positives, we may be able to accept that tradeoff, as long as users of the measure understand its limitations.
In addition to weighing the scientific acceptability, we may also want to describe the properties of measures along other domains.
- Impact. Does a measure affect just a small number of patients — for example, knee replacement cases — or a large subset of them?
- Potential for harm. What degree of harm could result from a given complication or condition?
- Opportunity for improvement. Measures are more likely to distinguish high-performing hospitals from low-performing ones when there is greater variation in scores. It may look good to deliver a given vaccine in 97 percent of appropriate cases, but if a strong majority of hospitals are at 95 percent or above, that score isn’t as powerful.
These, as well as strength of evidence, were the criteria used by The Leapfrog Group in deciding how to weigh measures that were included in its composite rating of patient safety, the Hospital Safety Score. (Disclosure: I provide scientific guidance to The Leapfrog Group on this score.)
Dearth of Research into How Measures Perform
The studies that have been conducted on the performance of performance measures are just scratching the surface. In addition to hundreds of measures used by the federal government in its various programs, there are dozens more used by states, regional collaboratives and private health plans. The scientific value of these measures is rarely disclosed.
For example, aside from the recent blood clot study, there have been virtually no published independent studies into the predictive value of Maryland Hospital Acquired Conditions measures. However, up to 4 percent of Maryland hospital Medicare payments depend on their combined score on these measures.
We need to get a better grasp of how well such measures are performing. Who can take on this work?
In the past, colleagues and I have made the case for a “Securities and Exchange Commission” for health care performance measures. In this concept, an entity would help set criteria for measures and transparently report on how they perform. We would have third-party auditing of the data that are publicly reported, and we would have an entity that could enforce compliance with the principles. This concept would hopefully ensure that all public quality measure data use standard methods of data collection and analysis, and it would allow apples-to-apples comparisons across provider organizations.
Measuring and public reporting of health care quality is a little bit of the Wild West these days. The frontiers of this field are expanding rapidly, and we find it difficult for our historical approach to measurement and reporting to keep pace. It’s time that we take a step back and make sure that the measures we use are truly providing the transparency that patients, hospitals, providers and the public are seeking from them.
Matt Austin is a professor at the Armstrong Institute with Johns Hopkins University.
Categories: Uncategorized








“Assessing the Performance of Performance Measures”
__
So-called CQMs: They’re “Process Indicators,” not “Clinical Quality Measures”
http://regionalextensioncenter.blogspot.com/2015/05/so-called-cqms-theyre-process.html