

Artificial Intelligence is at peak buzzword: it elicits either the euphoria of a technological paradise with anthropomorphic robots to tidy up after us, or fears of hostile machines breaking the human spirit in a world without hope. Both are fiction.
The Artificial Intelligences of our reality are those of Machine Learning and Deep Learning. Let’s make it simple: both are AI – but not the AI of fiction. Instead, these are limited intelligences capable of only the task they are created for: “weak” or “narrow” AI. Machine Learning is essentially applied Statistics, excellently explained in Hastie and Tibshirani’s Introduction to Statistical Learning. Machine Learning is a more mature field, with more practitioners, and a deeper body of evidence and experience.
Deep Learning is a different animal – a hybrid of Computer Science and Statistics, using networks defined in computer code. Deep Learning isn’t entirely new – Yann LeCun’s 1998 LeNet network was used for optically recognizing 10% of US checks. But the compute power necessary for other image recognition tasks would require an additional decade. Sensationalism by overly optimistic press releases co-exists with establishment inertia and claims of “black box” opacity. For the non-practitioner, it is very difficult to know what to believe, with confusion the rule.
A game of chance
Inspiration is found in an unlikely place – the carnival sideshow where one can find Plinko: a game of chance. In Plinko balls or discs travel through a field of metal pins and land in slots at the bottom. With evenly placed pins and a center start, the probability of landing in the center slots is highest, and the side slots lowest. The University of Colorado’s PHET project has a fantastic simulation of Plinko you can run yourself. If you played the game 10,000 times counting how many balls land in each slot, the accumulated pattern would look like this:

It should look familiar – it’s a textbook bell curve – the Gaussian Normal distribution that terrorized us in high school math. Its usually good enough to solve many basic Machine Learning problems – as long as the balls are all the same. But what if the balls are different – green, blue, red? How can we get the red balls to go into the red slot? That’s a classification problem. We can’t solely rely upon the Normal distribution to sort balls by color.
So, let’s make our Plinko game board computerized, with a camera and the ability to bump the board slightly left or right to guide the ball more towards the correct color slot. There is still an element of randomness, but as the ball descends through the array of pins, the repeated bumps nudges it into the correct slot.

The colored balls are our data, and the Plinko board is our AI.
One Matrix to rule them all
For those still fearing being ruled by an all-powerful artificial intelligence, meet your master:

Are you terrified beyond comprehension yet?
Math can be scary – when you’re in middle school. Matrix Math or Linear Algebra is a tool for solving many similar problems simultaneously and quickly. Without getting too technical, matrices can represent many different similar equations, like we would find in the layers of an AI model. Its behind the AI’s that use Deep Learning, and partly responsible for the “magic”.
This ‘magic’ happened because of serendipitous parallel advances in Computer Science and Statistics, and similar advances in processor speed, memory, and storage. Reduced Instruction Set Chips (RISCs) allowed Graphics Processing Units (GPU’s) capable of performing fast parallel operations on graphics like scaling, rotations, and reflections. These are affine transformations. It turns out that you can define a shape as a matrix, apply matrix multiplication to it, and end up with an affine transformation. Precisely the calculations used in Deep Learning.
The watershed moment in Deep Learning is typically cited as 2012’s AlexNet, by Alex Krizhevsky and Geoffrey Hinton, a state of the art GPU accelerated Deep Learning network that won that year’s Imagenet Large Scale Visual Recognition Challenge (ILSVRC) by a large margin. Thereafter, other GPU accelerated Deep Learning algorithms consistently outperformed all others.
Remember our colored ball-sorter? Turn the board on its side, and it looks suspiciously like a deep neural network, with each pin representing a point, or node, in the network. A Deep neural network can also be named a Multi-Layer Perceptron (MLP) or an Artificial Neural Network (ANN) . Both are a layer of software “neurons” followed by 0-4 layers of “hidden” neurons which output to a final neuron. The output neuron typically will give an output of a probability, from 0 to 1.0, or 0% to 100% if you prefer.

The “hidden” layers are hidden because their output is not displayed. Feed the ANN an input, and the output probability pops out. This is why ANN’s are called “black boxes” – you don’t routinely evaluate the inner states, leading many to incorrectly deem them “incomprehensible” and “opaque”. There are ways to view the inner layers (but they may not be as enlightening as hoped).
Everything Old is New Again
The biggest problem was getting the network to work. A one-layer MLP was created in the 1940’s. You could only travel forward through the network (feed forward), updating the values of each and every neuron individually via a brute-force method. It was so computationally expensive with 1940-1960’s technology that it was unrealistic for larger models. And that was the end of that. For a few decades. But smart mathematicians kept working, and had a realization.
If we know the inputs and the outputs of a neural net, we can do some maneuvering. A network can be modeled as a number of Matrix operations, representing a series of equations (Y=mX+b, anyone?). Because we know both inputs & outputs, that matrix is differentiable; i.e. the slope(m), or first derivative, is solvable. That first derivative is named the gradient. Application of Calculus’ chain rule enables the gradient of the network to be calculated in a backward pass. This is Backpropagation. Hold that thought – and my beer – for a moment.
By the way, while Backpropagation was solved in the 1960’s, it was not applied to AI until the mid 1980’s. The 50’s-80’s are often referred to as the First AI ‘winter’.
Go back to Plinko; but turn it upside down. This time, we won’t need to nudge it. Instead, let’s color the balls with a special paint – its wet, so it comes off on any pin it touches, and its magnetic, only attracting balls of the same color. Feeding the colored balls from their respective slots, they’ll run down by gravity, colored paint rubbing off on the pins they touch. The balls then exit from the apex of the triangle. It would look suspiciously like Figure 5, rotated 90 degrees clockwise.

After running many wet balls through, looking at our board, the pins closest to the green slot are the greenest, pins closest to the red slot reddest, and the same for blue. Mid-level pins in front of red and blue become purple, and mid-level pins in front of blue and green become cyan. At the apex, from mixing the green, red, and blue paint the pins are a muddy color. The amount of specific color paint deposited on the pin depends on how many balls of that color hit that individual pin on their random path out. Therefore, each pin has a certain amount of red, green, and/or blue colored paint on it. We actually just trained our Plinko board to sort colored balls!
Turn the model rightside up and feed it a green paint colored ball in from the apex of the pyramid. Let’s make the special magnetic paint dry this time.
The ball bounces around, but it is generally attracted to the pins with more green paint. As it passes down the layers of pins, it orients first towards the cyan pins, then those cyan pins with the most green shading, then the purely green pins before falling in the green slot. We can repeat the experiment with blue or red balls, and they will sort similarly.
The pins are the nodes, or neurons in our Deep Learning network, and the amount of paint of each color is the weight of that particular node.
Sharpen your knives, for here comes the meat.
Let’s look at an ANN, like the one in figure 5. Each neuron, or node, in the network will have a numerical value, a weight assigned to it. When our neural network is fully optimized, or trained, these weights will allow us to correctly sort, or classify the inputs. There is a constant, the bias, that also contributes to every layer.
Remember the algebraic Y=mX+b equation? Here is its deep learning equivalent:
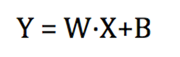
The overly simplified neural network equation has W representing the weights, and B the bias for a given input X. Y is the output. As both the weights W and the input X are matrices, they are multiplied by a special operator called a Dot Product. Without getting too technical, the dot product is multiplying matrices in such a way that their dimensions are maintained and their similarities are grown/enhanced.
In figure 5 above, the bias is a circle on top of each layer with a “1” inside. That value of 1 avoids multiplying by zero, which would clear out our algorithm. Bias is actually the output of the neural network when the input is zero. Why is it important? Bias allows us to solve the Backpropagation algorithm by solving for the network’s gradients. The network’s gradients will allow us to optimize the weights of our network by a process known as gradient descent.
On a forward pass through the network, everything depends on the loss function. The loss function is simply a mathematical distance between two data points: X2-X1. Borrowing the old adage, “birds of a feather flock together”, data points with small distances between each other will tend to belong to the same group, or class, and data points with a distance more akin to Kansas and Phuket will have no relationship. It is more typical to use a loss function such as a root mean squared function, but many exist.
First, let’s randomize all the weights of our neural network before starting and avoid zeroes and ones which can cause our gradients to prematurely get too small (vanishing gradients) or too large (exploding gradients).
To train our network, a known (labeled) input runs forward through the network. On this randomly initialized network, we know this first output (Y%) will be garbage – but that’s OK! Knowing what this input’s label is – its ground truth – we will now calculate the loss. The loss is the difference between 100% and the output Y, i.e. (100%-Y%).
We want to minimize that loss; to try to get it as close to zero as possible. That will indicate that our neural network is classifying our inputs perfectly – outputting a probability of 100% (zero uncertainty) for a known item. To do so, we are going to adjust the weights in the network – but how? Recall Backpropagation. By calculating the gradients of the network, we can adjust the weights of the network in a small step-wise fashion away from the gradient, which is towards zero. This is stochastic gradient descent and the small step-wise amount is the learning rate. This should decrease the loss and yield a more accurate output prediction on the next run through, or iteration, of the network on that same data. Each input is an opportunity to adjust, or learn, the best weights. And typically you will iterate over each of these inputs 10, 20, 100 (or more) times, or epochs, each time driving the loss down and adjusting the weights in your network to be more accurate in classifying the training data.
Alas, perfection has its drawbacks. There are many nuances here. The most important is to avoid overfitting the network too closely to the training data; a common cause of real-world application failure. To avoid this, datasets are usually separated into training, validation, and test datasets. The training dataset teaches your model, the validation dataset helps prevent overfitting, and the test dataset is only used once for final measurement of accuracy at the end.
One of the more interesting features of deep learning is that deep learning algorithms, when designed in a layered, hierarchical manner, exhibit essentially self-organizing behavior. In a 2013 study on images, Zeiler and Fergus (1) showed that lower levels in the algorithm focused on lines, corners, and colors. The middle levels focused on circles, ovals, and rectangles. And the higher levels would synthesize complex abstractions – a wheel on a car, the eyes of a dog.

Why this was so exciting was prior Visual Evoked Potentials on the primary visual cortex of a cat showed activations by simple shapes uncannily similar to the appearance of the first level of the algorithm, suggesting this organizing principle is present both in nature and AI.
Evolution is thus contingent on… variation and selection (attr. Ernst Mayer)
ANN’s/MLP’s aren’t that useful in practice as they don’t handle variation well – i.e. your test samples must match the training data exactly. However, by changing the hidden layers, things get interesting. An operation called a convolution can be applied to the data in an ANN. The input data is arranged into a matrix, and then gone over stepwise with a smaller window, which performs a dot product on the underlying data.
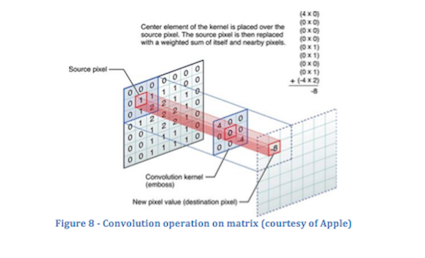
For example, take an icon, 32 pixels by 32 pixels with 3 color channels to that image (R-G-B). We take that data, arrange it into a 32x32x3 matrix, and then convolve over the matrix with a 3×3 window. This transforms our 32×32 matrix into a 16×16 matrix, 6 deep. The process of convolving creates multiple filters – areas of pattern recognition. In training, these layers self-organize to activate on similar patterns found within the training images.
Multiple convolutions are generally performed, each time halving the size of the matrix while increasing its depth. An operation called a MaxPool is frequently performed after a series of convolutions to force the model to associate these narrow windowed representations to the larger data set (an image, in this case) by downsampling.

This Deep Learning network composed of convolutional layers is the Convolutional Neural Network (CNN). CNN’s are particularly well suited to image classification, but can also be used in voice recognition or regression tasks, learning both variation and selectivity, with some limitations. Recent published research has claimed human level performance in medical image identification. (4) CNN’s are powerful, with convolutional layers assembling simple blocks of data into more complex and abstract representations as the number of layers increases. These complex and abstract representations can then be identified anywhere in the image.
One drawback to CNN’s is that increasing model power requires increased model depth. This increases the number of parameters in the model, lengthening training time and predisposing to the vanishing gradient problem, where gradients disappear and the model stalls in stochastic gradient descent, failing to converge. The introduction of Residual Networks in 2015 (ResNets) solved some of the problems with increasing network depth, as residual connections (seen above in a DenseNet) allow backpropagation to take a gradient from the last layer and follow it through all the way to the first layer. Recognition that CNN’s are agnostic to position, but not orientation is important to note. Capsule Networks were recently proposed to address orientation limitations of CNN’s.
The Convolutional network is one of the easier Deep Learning algorithms to peer inside. Figure 7 does exactly that, using a deconvolutional network to show what selected levels of the algorithm are “seeing”. While these patterns are interesting, they may not be easily evident depending upon the learning set. To that aim, GRAD-CAM models based on the last convolutional layer before the output have been designed, producing a heatmap to explain why the CNN chose the classification it did. This was a test on ImageNet data for the “lion” classifier:

There are quite a number of Convolutional Neural Networks available for experimentation. ILSVRC winners like AlexNet, VGG-16, ResNet-152, GoogLeNet, Inception, DenseNets, U-Nets are most commonly used, with newer networks like NAS-Net and Se-Net approaching state of the art (SOTA). While a discussion of the programming languages and hardware requirements to run neural networks is beyond the scope of this work, a guide to building a deep learning computer is available on the net, and many investigators use the Python programming language with PyTorch or Tensorflow and its slightly easier to use cousin, Keras.
Sequenced or temporal data needs a different algorithm – a LSTM (Long-Short-Term Memory), which is one of the Recurrent Neural Networks (RNN’s). RNN’s feed their computed output back into themselves. The LSTM module feeds information into itself in two ways – a short term input, predicated only on the prior iteration; and a long term input, re-using older computations. This particular algorithm is particularly well suited to such as text analysis, Natural Language Processing (NLP), and image captioning. There is a great deal of unstructured textual data in medicine – RNN’s performing NLP will probably be part of that solution. The main problem with RNN’s is their recurrent, iterative nature. Training can be lengthy – 100x as long as a CNN. Google’s language translation engine reportedly uses a LSTM seven layers deep, the training of which must have been immense in time and data resources. RNN’s are generally considered an advanced topic in deep learning.
Another advanced topic are Generative Adversarial Networks (GAN’s): two neural networks in parallel, one of which generates simulated data, and the other of which evaluates or discriminates that data in a competitive, or adversarial fashion. The generator generates data to pass the discriminator. As the discriminator is fed more data by the generator, it becomes better at discriminating. So both spur higher achievement until the discriminator can no longer tell that the generator’s simulations are fake. GAN’s use in healthcare appear to be mostly for simulating data, but the possibility of pharmaceutical design and drug discovery has been proposed as a task for GAN’s. GAN’s are used in style transfer algorithms for computer art, as well as creating fake celebrity photos and videos.
Deep reinforcement learning (RL) is briefly mentioned – it is an area of intense investigation and appears useful in temporal prediction. However, few healthcare applications have been attempted with RL. In general, RL is difficult to work with and still mostly experimental.
Finally, not every problem in medicine needs a deep learning classifier applied to it. For many applications, simple rules and linear models work reasonably well. Traditional supervised machine learning (i.e. applied statistics) is still a reasonable choice for rapid development of models, namely techniques such as dimension reduction, principal component analysis (PCA), Random Forests (RF), Support Vector Machines (SVM) and Extreme Gradient Boosting (XGBoost). These analyses are often done not with the previously mentioned software, but with a freely available language called ‘R’. The tradeoff between the large amount of sample data, compute resources, and parameter tuning a deep learning network requires vs. a simpler method which can work very well with limited data should be considered. Ensembles utilizing multiple deep learning algorithms combined with machine learning methods can be very powerful.
- My Brain is the key that sets me free. – Attr. Harry Houdini
Magic is what deep learning has been compared to, with its feats of accurate image and facial recognition, voice transcription and language translation. This is inevitably followed by the fictive “there’s no way of understanding what the black box is thinking”. While the calculations required to understand deep learning are repetitive and massive, they are not beyond human comprehension nor inhumanly opaque. If these entities have now been demystified for you, I have done my job well. Deep Learning remains an active area of research for me, and I learn new things every day as the field advances rapidly.
Is deep learning magic? No. I prefer to think of it as alchemy – turning data we once considered dross into modern day gold.
- Visualizing and Understanding Convolutional Networks, MD Zeiler and R Fergus, ECCV 2014 part I LNCS 8689, pp 818-833, 2014.
- DH Hubel and TN Weisel J Physiol. 1959 Oct; 148(3): 574–591.
- G Huang, Z Liu, L van der Maaten et al Densely Connected Convolutional Networks arXiv:1608.06993
- P Rajpurkar, J Irvin, K Zhu, et al. ChexNet: Radiologist-level Pneumonia Detection on Chest X-rays with Deep Learning. arXiv:1711.05225 [cs.CV]
Stephen M Borstelmann MD is an interventional radiologist and published medical AI researcher/speaker with an interest in operations.
Categories: Uncategorized








Artificial intelligence is a fragment of computer science that creates intelligence in computers or machines. The father of AI John McCarthy defines it as the science and engineering of creating intelligent computer systems, specifically computer programs. The AI in healthcare software utilizes an algorithm to equip human insights to evaluate complicated medical data between the prevention technique and patient outcome.
Read our article for more information: https://www.inkwoodresearch.com/global-artificial-intelligence-in-healthcare-market-to-hit-at-40-03-cagr/
What a delightful romp! Thanks.
(Dr. Borstelmann, you have too much time on your hands.)
This makes my morning.
LOL. See my post http://regionalextensioncenter.blogspot.com/2017/05/assuming-despite-if-then-therefore-else.html
AND my mid-life patient with psoriatic arthritis, ulcerative colitis, asthma, adult onset Type I Diabetes Mellitus and sleep apnea — on how to manage his chronic pain problem without narcotics (at the time of my retirement)?
I want AI to be able to read “Inborn Metabolic Disease: Diagnoses and Treatment” 6th ed, 658 pages, by Jean-Marie Saudubray and advise me on a current patient.